Abstract

Previous methods for inserting new subjects (e.g., face identities and cats) into pre-trained Text-to-Image diffusion models for personalized generation have two problems: (1) Attention Overfit : As shown in the activation maps of Textual Inversion and Prospect, their ‘‘V’’ attention nearly takes over the whole images, which means the learned embedding try to encode both the target subject and subject-unrelated information in the target images, such as the subject region layout and background. This problem extremely limits their interaction with other existing concepts such as ‘‘cup’’, which results in the failure of generating the image content aligned with the given prompt. (2) Limited Semantic-Fidelity: Despite they alleviate overfit by introducing subject prior such as face recognition models, the ‘‘cup’’ attention of Celeb Basis still affects the ‘‘V’’ face region and this limitation hinders the control of subject attributes such as ‘‘eyes closed’’, while IP-Adapter learns mismatched subject embedding (i.e., its attention of ‘‘V*’’ is inconsistent with the generated face). These flaws result in the limited semantic-fidelity of text-to-image generation. Therefore, we propose Subject-Wise Attention Loss and Semantic-Fidelity Token Optimization to address problem (1) and (2) respectively.
Framework
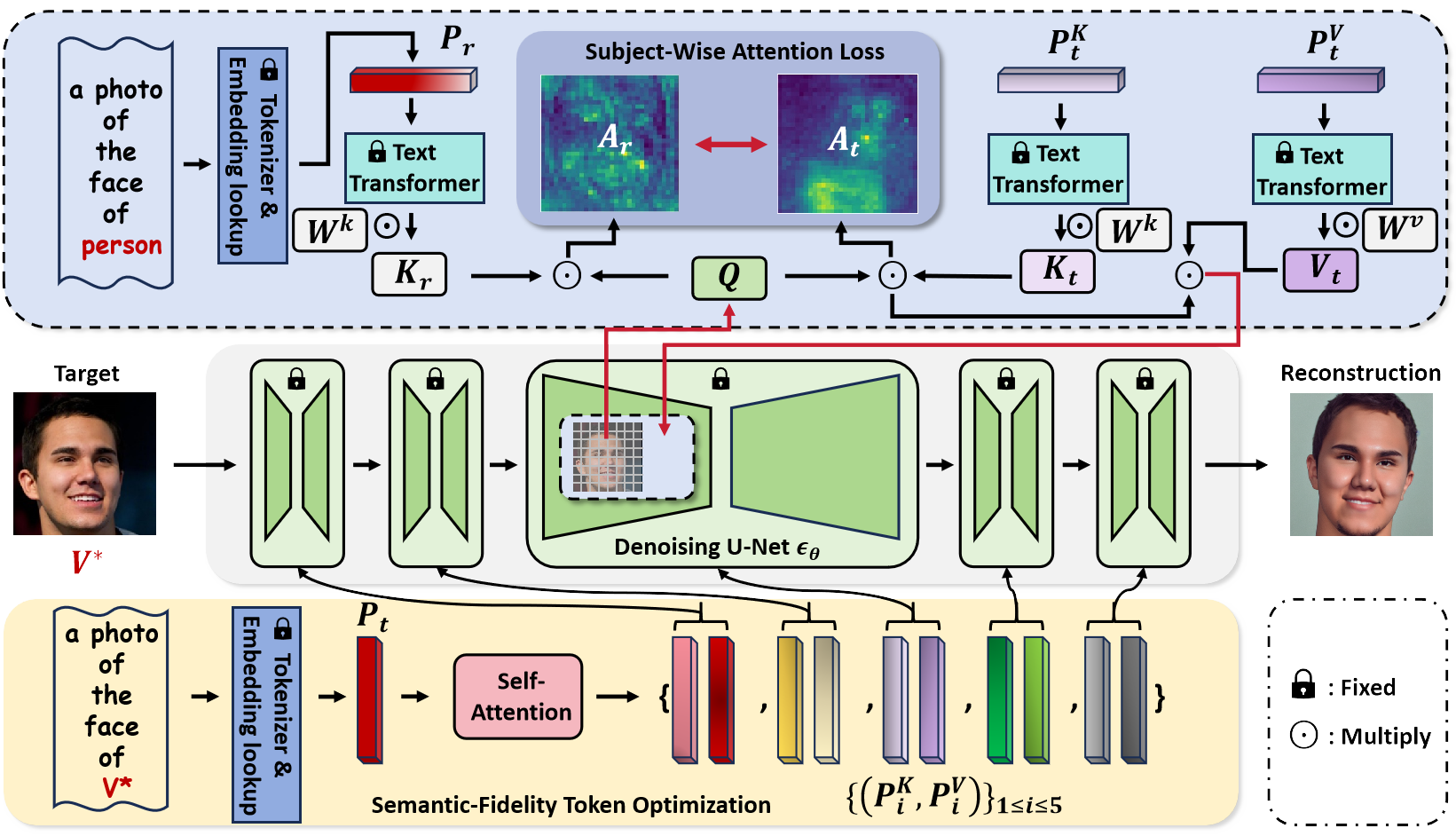 The overview of our framework. We first propose a novel Subject-Wise Attention Loss to alleviate the attention overfit problem and make the subject embedding focus on the subject region to improve subject accuracy and interactive generative ability. Then, we optimize the target subject embedding as five per-stage tokens pairs with disentangled features to expend textural conditioning space with Semantic-Fidelity control ability.
The overview of our framework. We first propose a novel Subject-Wise Attention Loss to alleviate the attention overfit problem and make the subject embedding focus on the subject region to improve subject accuracy and interactive generative ability. Then, we optimize the target subject embedding as five per-stage tokens pairs with disentangled features to expend textural conditioning space with Semantic-Fidelity control ability.
Motivation
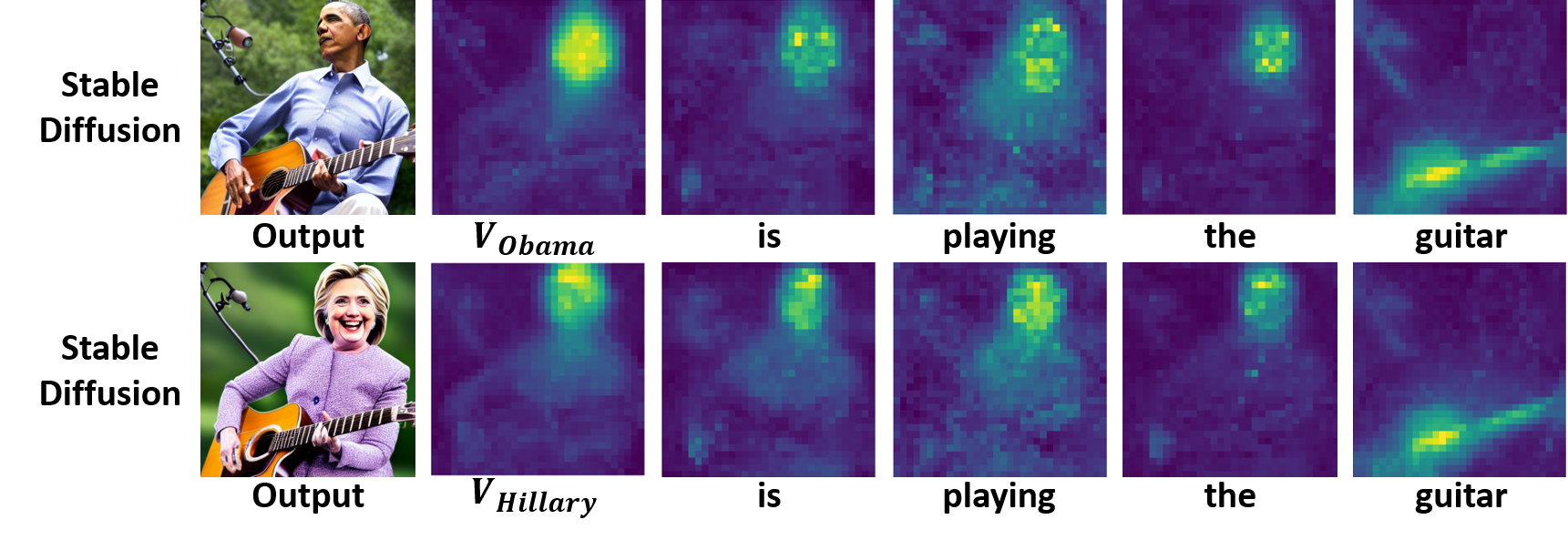 We note that T2I models have learned a robust general concept prior for various subcategories, e.g., different human identities falling under the broad concept of ‘‘person’’, which could act as an anchor for regularizing subject embedding. Furthermore, when ‘‘Obama’’ is replaced with ‘‘Hillary’’ in prompts, the attention maps for each token remain similar. Thus, we propose the subject-wise attention loss, which encourages the effect of each token to align with those from a reference prompt for dual optimization of controllability and subject similarity.
We note that T2I models have learned a robust general concept prior for various subcategories, e.g., different human identities falling under the broad concept of ‘‘person’’, which could act as an anchor for regularizing subject embedding. Furthermore, when ‘‘Obama’’ is replaced with ‘‘Hillary’’ in prompts, the attention maps for each token remain similar. Thus, we propose the subject-wise attention loss, which encourages the effect of each token to align with those from a reference prompt for dual optimization of controllability and subject similarity.
 When it comes to the generation of images with controllable attributes, previous methods fail to generate examples like ‘‘an old person’’. By analyzing the generation process of Stable Diffusion, we believe this is due to two reasons: (1)Attention Mismatch: The ${K}$ feature cooperates with the image feature ${Q}$ to decide how to sample from the feature ${V}$. However, the attention map is unmatched for prompts like ‘‘beard’’ or ‘‘closed’’. (2)Insufficient ${V}$ Feature: Even with a similar attention map (same $K$), the $V$ feature from prompt ‘‘an old Emma Watson/Rich Sommer’’, functioning as a provider of detailed texture features, may not adequately represent the ‘‘old’’ on them. We address this challenge by setting different $K$ or $V$ while keeping the other same as comparison methods. This observation underscores the impact of separately optimizing embeddings for $K$ and $V$ in facilitating semantic-fidelity generation.
When it comes to the generation of images with controllable attributes, previous methods fail to generate examples like ‘‘an old person’’. By analyzing the generation process of Stable Diffusion, we believe this is due to two reasons: (1)Attention Mismatch: The ${K}$ feature cooperates with the image feature ${Q}$ to decide how to sample from the feature ${V}$. However, the attention map is unmatched for prompts like ‘‘beard’’ or ‘‘closed’’. (2)Insufficient ${V}$ Feature: Even with a similar attention map (same $K$), the $V$ feature from prompt ‘‘an old Emma Watson/Rich Sommer’’, functioning as a provider of detailed texture features, may not adequately represent the ‘‘old’’ on them. We address this challenge by setting different $K$ or $V$ while keeping the other same as comparison methods. This observation underscores the impact of separately optimizing embeddings for $K$ and $V$ in facilitating semantic-fidelity generation.
Results
Single Person's Generation
Single Person’s Comparisons
Various scenes, actions, and facial attributes manipulation


Various face photo generation or ours and comparison methods
More Single Person’s Generation Results

Multiple Persons' Generation
Multiple Persons’ Comparisons
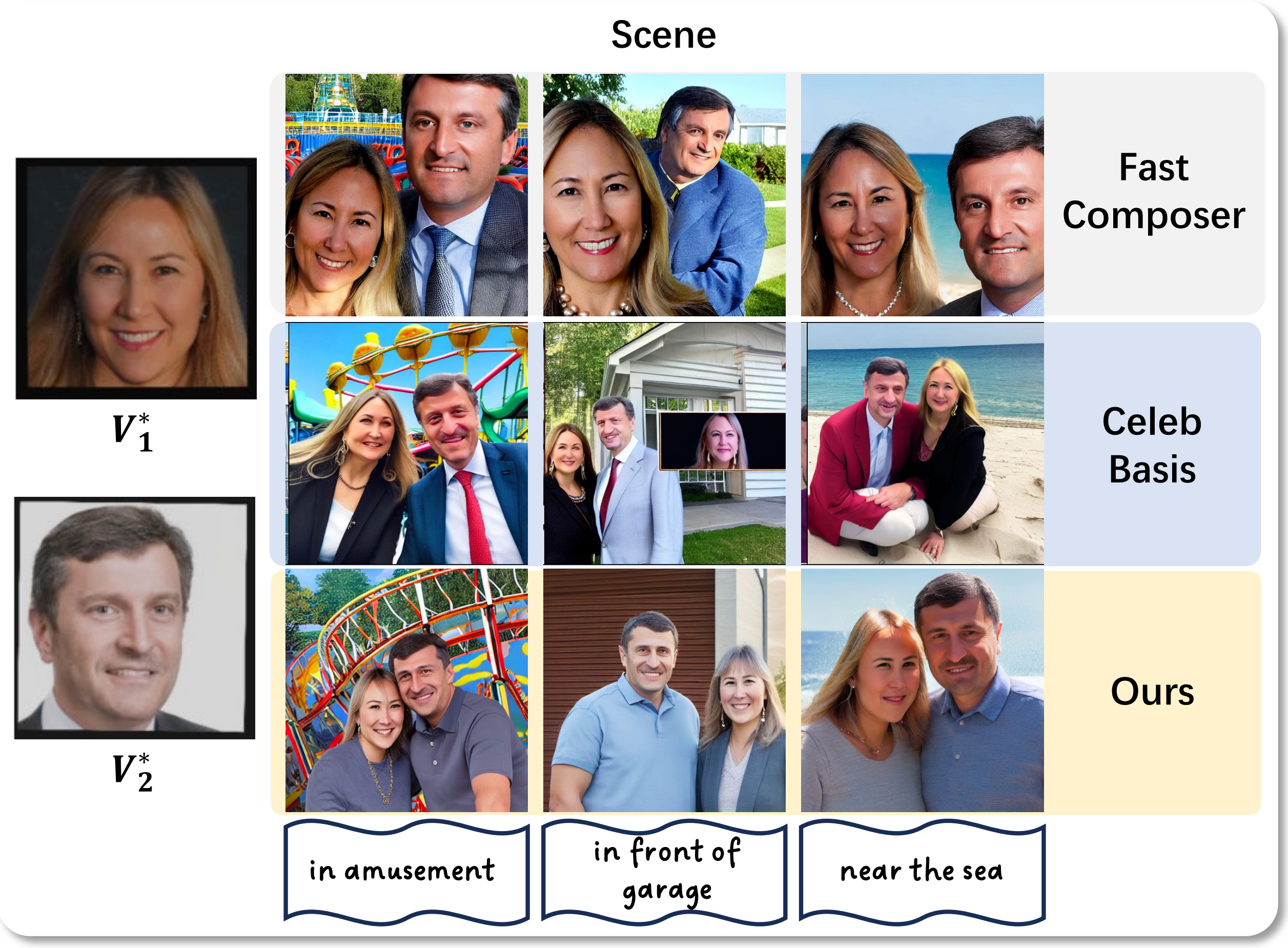

More Multiple Persons’ Gneration Results

More Evaluation
Ablation
Choice of $\lambda$
With a small $\lambda$ value, the learned embedding would overfit to the target subject. Relatively, employing a larger $\lambda$ ($0.01$ or $0.05$) leads to underfitting of the optimized embedding to the target subject (lower subject similarity). $\lambda=0.003$ would be the best choice.

Attention Loss
Comparing Subject-Wise Attention Loss with existing attention regularization techniques.



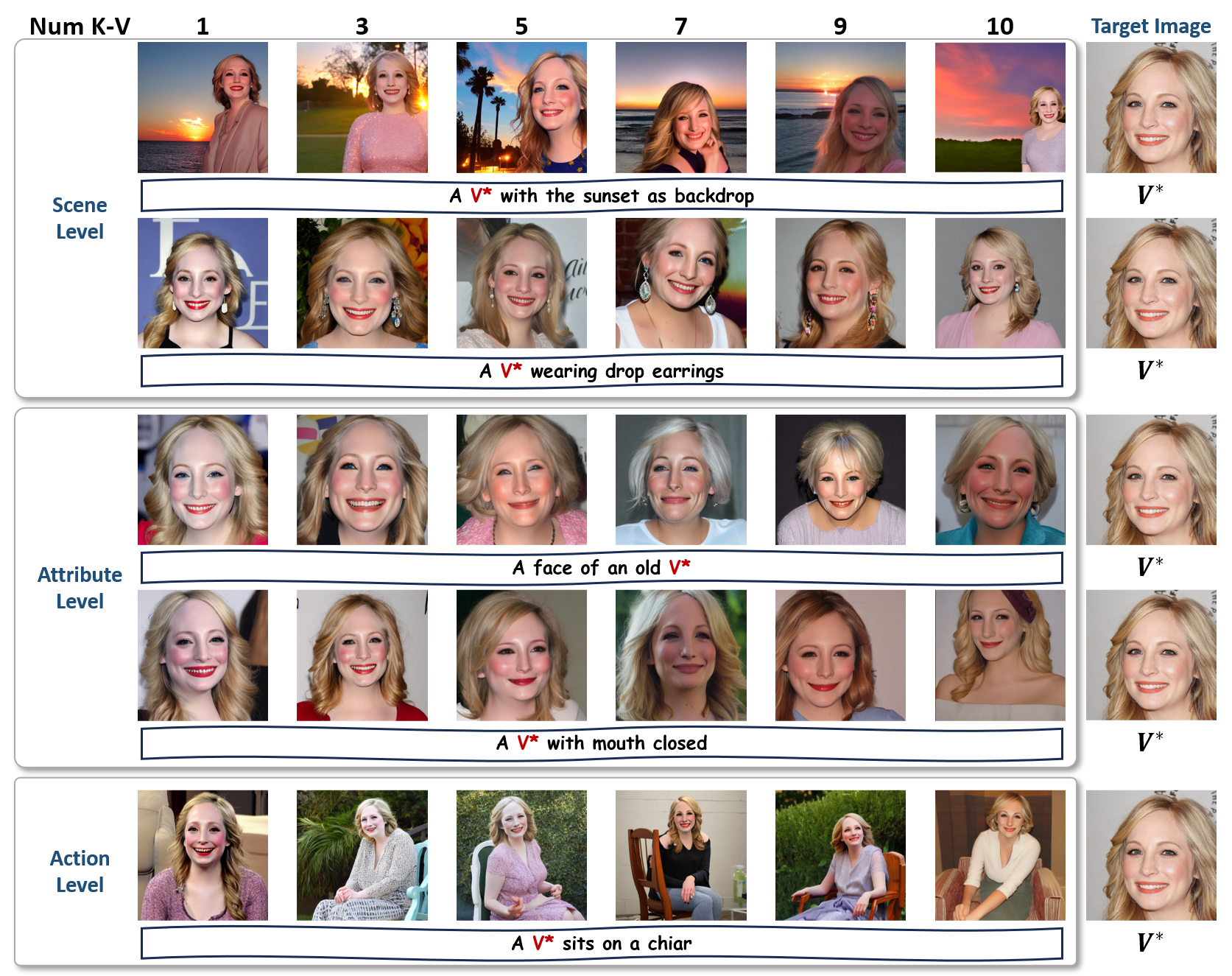
Number of K-V pairs
A sensitivity analysis of the Number of K-V Feature Pairs.
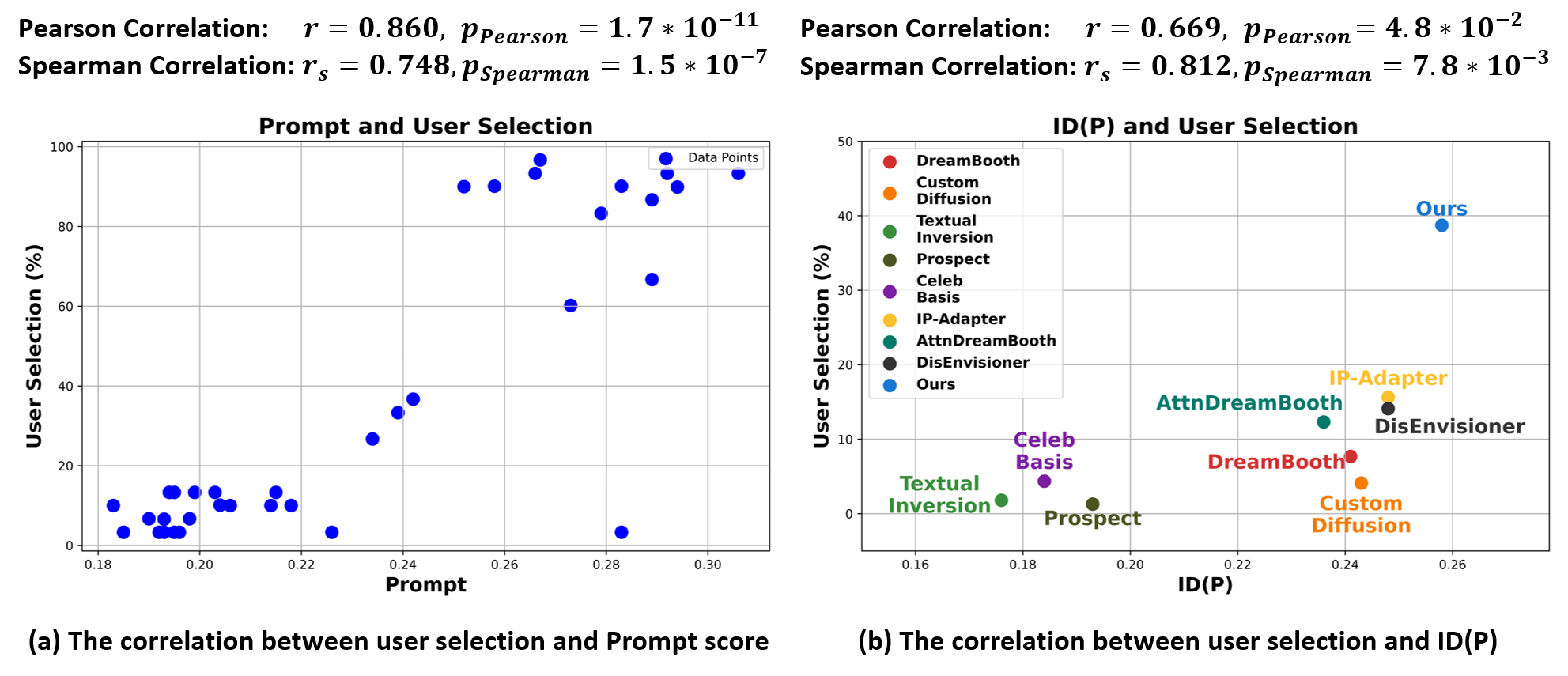
Correlation of user selection with ID(P) metric
We analyze the correlation between user selection with Prompt score and ID(P) score.
Embedding Other Objects
Various subject generation or ours and comparison methods
Our method does not introduce face prior from other models, we adopt animals (Bear, Cat, and Dog) and general objects (Car, Chair, and Plushie) for experiments, which show the generalization ability of our method.

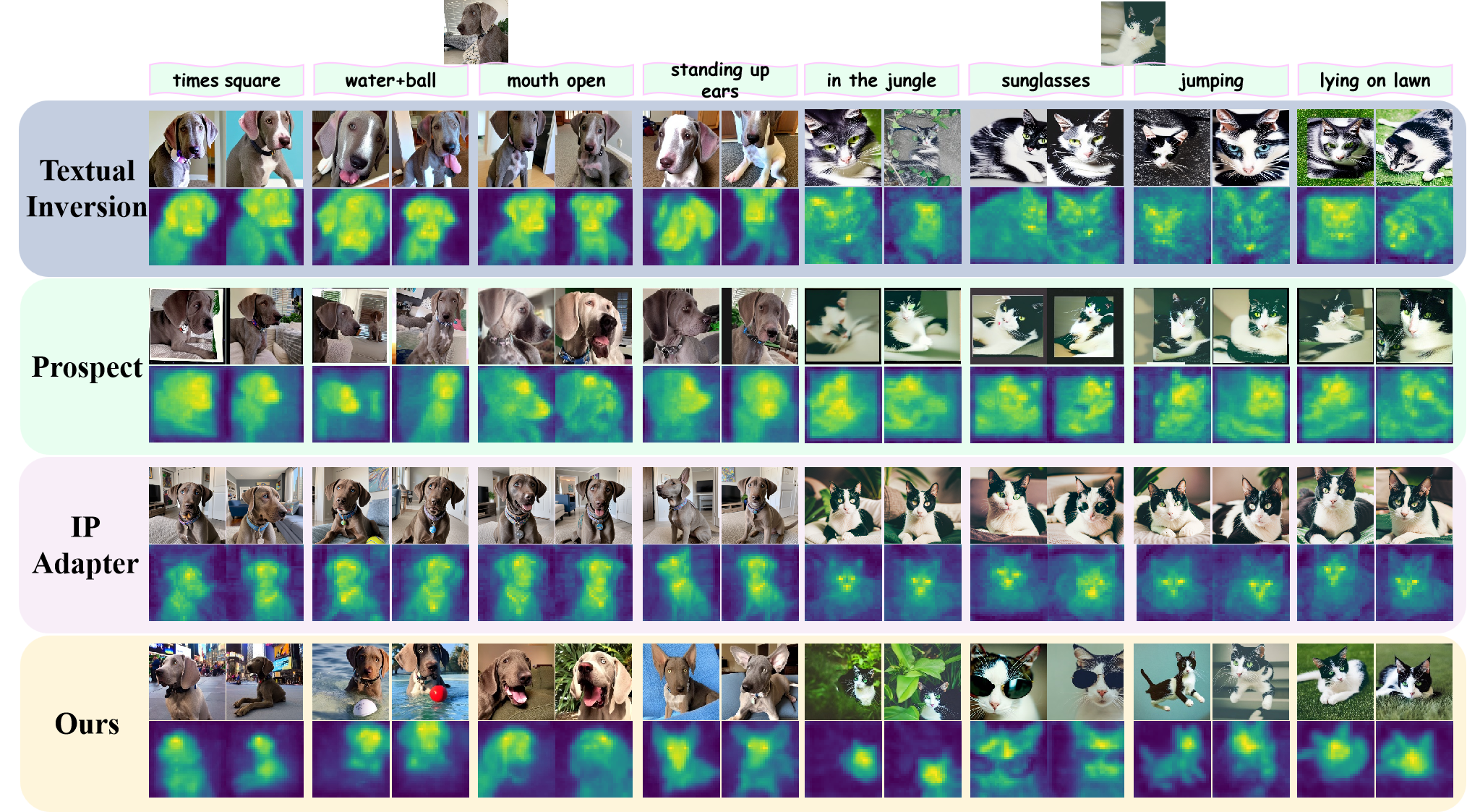
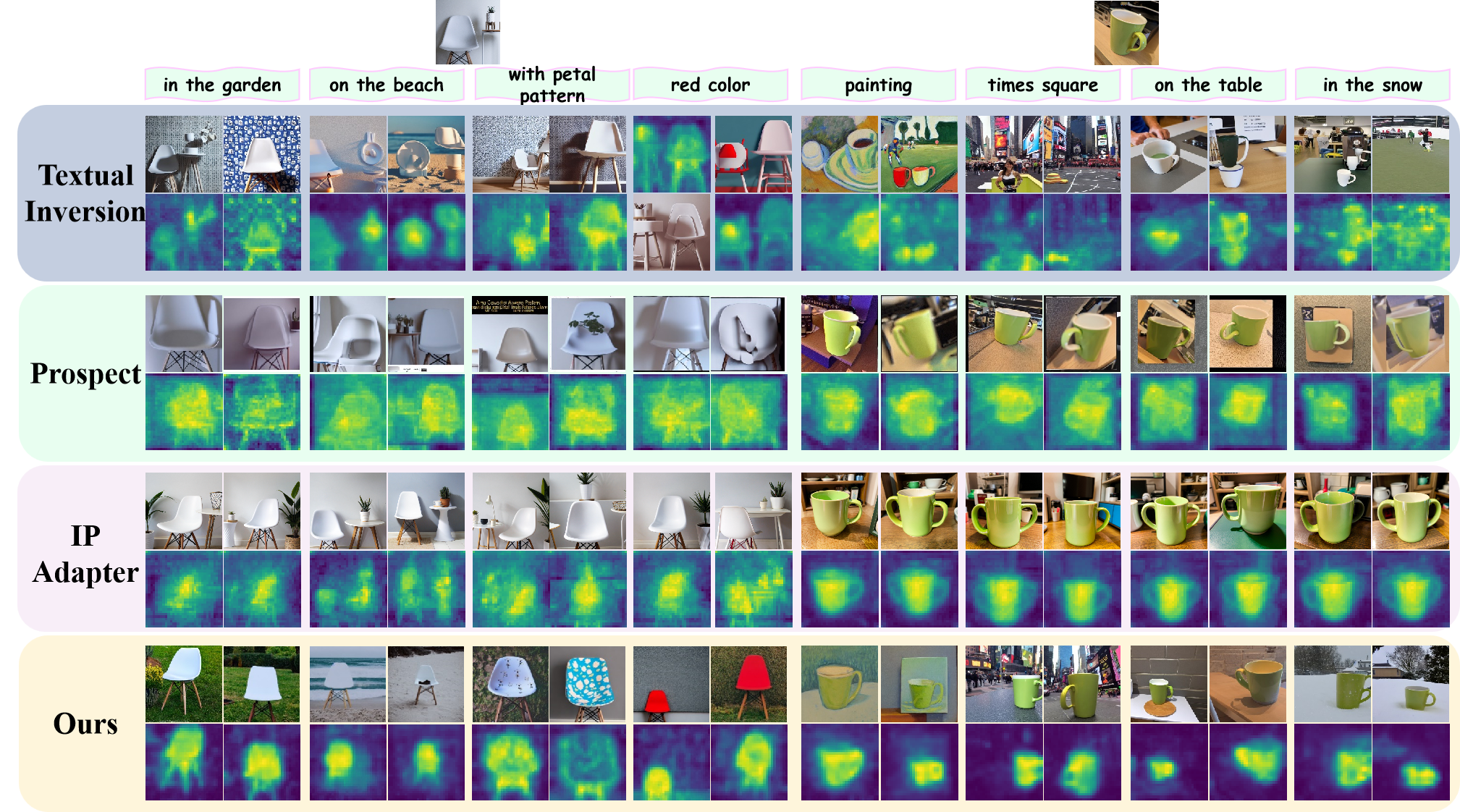
Various scenes, actions, and attributes manipulation

Using Stable Diffusion XL
We select SDXL model stable-diffusion-xl-base-1.0 as the target model and the newly released methods using it for comparison.

Combining with ControlNet

Limitation
Inherent limitations of current models persist, including semantic confusion in multiple similar concept generation and complex control (e.g., “winking” and “full of books”).
